介绍
千里之行,始于足下
GrowingIO JS SDK 支持 IE11 浏览器、360 浏览器、谷歌浏览器、搜狗浏览器、火狐浏览器、QQ 浏览器、Safari 浏览器、Maxthon、Mobile 端浏览器,并且全面支持 H5,覆盖市面上主流的浏览器。只要在 layout 文件里面加入几行代码,就可以集成 GrowingIO 的 JS SDK,可以采集用户的行为数据。
<script type="text/javascript">
!(function (e, n, t, s, c) {
var o;
e[s] =
e[s] ||
function () {
(e[s].q = e[s].q || []).push(arguments);
};
(c = c || 'vds'),
(e._gio_local_vds = c),
(e[c] = null !== (o = e[c]) && void 0 !== o ? o : {}),
(e[c].namespace = s);
var d = n.createElement('script');
var i = n.getElementsByTagName('script')[0];
(d.async = !0), (d.src = t), i.parentNode.insertBefore(d, i);
})(window, document, 'https://assets.giocdn.com/sdk/webjs/gdp-full.js', 'gdp');
</script>
当用户加载页面的时候,会异步加载 JS SDK,不会影响到用户的加载速度,所以一般建议把这段代码加入到 <head></head> 的最下面,这样能最大限度的保证数据采集的完整性。如果有限制只能加入到 <body></body> 的最下面,也是可以的,这样潜在可能会丢失掉那些一加载页面就立刻关闭的数据,不过概率也并不高。
当用户加载你的网页的时候,会依次进行下列动作:
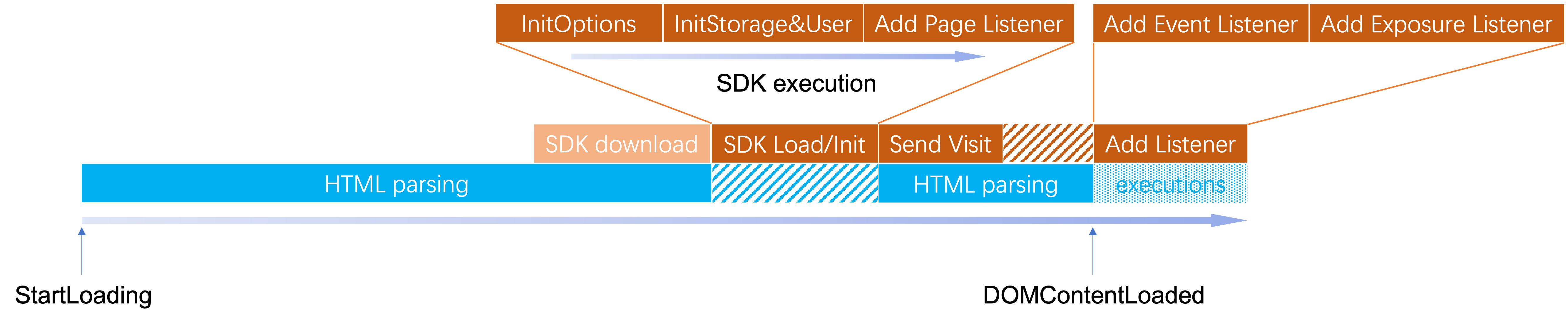
所以,可以从图中看到,访问数据不需要等待 DomContentLoaded 时间,取决于页面的复杂度,最大限度的保证访问数据的准确性。当页面内容加载完成后,SDK 会随后启动交互行为跟踪和 DOM 内容变化跟踪。这样,就能自动地采集到用户在网站上看到的内容和交互动作。
当 SDK 加载后,会自动开始采集以下三类数据:
用户访问数据: 网站访客在何时何地访问了哪个网页,收集包括域名、页面路径、浏览器、操作系统、屏幕分辨率、访问来源、用户唯一标识 ID、访问唯一标识 ID、访问时间、页面标题等信息。
**行为数据:**用户在网站上的交互行为,比如点击链接、提交表单、修改选择,都会被自动采集,内容包括交互元素的页面信息、交互行为类型、交互元素的标记 ID、交互元素的内容、交互元素的超链接、交互元素的位置信息。SDK 不采集除搜索框外任何用户在表单里输入的信息。
**内容数据:**当用户访问网站时,用户看到的内容即页面出现的元素,会被自动采集,包括内容所在的页面信息、元素的标记 ID、文本内容、超链接、位置信息。
而实现自动数据采集,GrowingIO 主要是依赖浏览器的以下两个特性:
DOM 树结构
当用户打开网页时,会从服务器获取到 HTML 文件并渲染成 DOM 树结构,比如对于下面的 HTML 代码:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8" />
<title>GrowingIO</title>
</head>
<body>
<div class="image">
<img src="https://oss-cn-hangzhou.aliyuncs.com/GIO.png" alt="GioPicture" />
</div>
<div class="header">
<h1 id="slogan">增长,源于对每一个用户行为的洞察</h1>
</div>
<h2 id="subtitle">为产品和运营打造的数据分析产品</h2>
<form class="register">
<button>免费试用</button>
</form>
</body>
</html>
这�段 HTML 代码会被渲染成这样的结构:

每一个框对应都是一个 DOM 对象,也是我们无埋点采集和匹配的基础。换一种呈现方式,用可视化树的方式,是这样的:
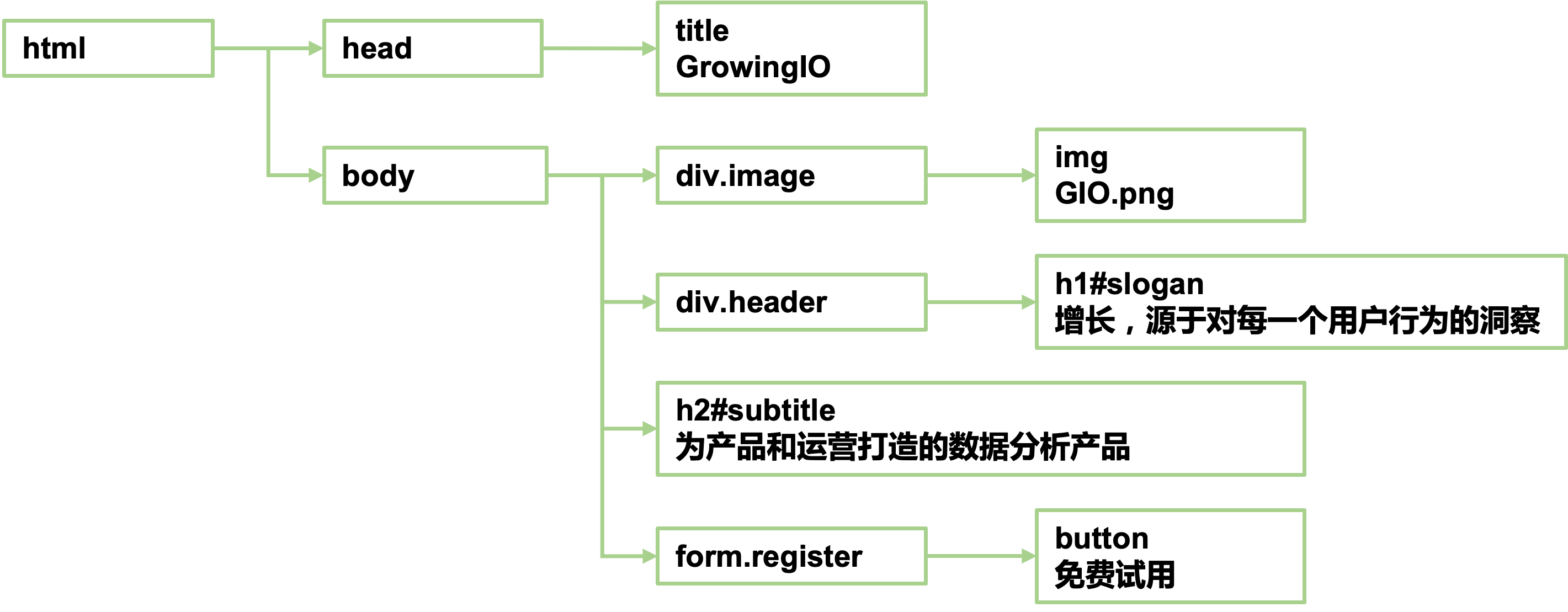
在上面的例子中,当页面加载后,SDK 会采集 body 下的所有节点(SDK本身只会采集内部节点深度小于等于5的节点事件,上文例子中没有节点深度超过5,所以会被全部采集),也就是 div 节点、img 节点、h1 节点、h2 节点、form 节点和 button 节点。
- div 节点的数据结构是
{ xpath: '/h1', xcontent: '/#slogan' }; - img 节点的数据结构是
{ xpath: '/div/img', xcontent: '/.image/-', textValue: 'GioPicture' }; - h1 节点的数据结构是
{ xpath: '/div/h1', xcontent: '/.header/#slogan', textValue: '增长,源自对每一个用户行为的洞察' }; - h2 节点的数据结构是
{ xpath: '/h2', xcontent: '/#subtitle', textValue: '为产品和运营打造的数据分析产品' }; - form 节点的数据结构是
{ xpath: '/form', xcontent: '/.register' }; - button 节点的数据结构是
{ xpath: '/form/button', xcontent: '/.register/-', textValue: '免费试用' };
通过这些数据我们也就知道,用户在网页里面�看到了哪些内容。
事件驱动模型
如其他 GUI 程序一样, 浏览器对于鼠标点击、键盘输入等用户交互行为,使用了非常简单的事件驱动模型来响应用户行为。开发者可以在代码中注册一个回调函数,当事件发生时,会从事件队列里寻找是否有对应的回调函数,找到的话就会被触发开始执行。
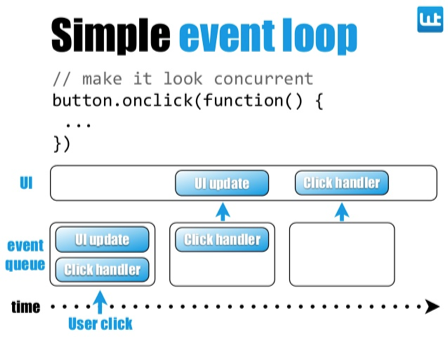
所以,当 SDK 被成功加载到页面的时候,会自动监听所有的点击事件、input/select 修改事件。当事件发生时,监听回调函数会触发,然后采集相对应的数据。
比如对于上文中的网页,如果用户点在 h1 的文本上,会采集到数据 { eventType: 'VIEW_CLICK', xpath: '/div/h1', xcontent: '/.header/#slogan', textValue: '增长,源自对每一个用户行为的洞察' }。